

Monitorare una pagina Web
Con monitoraggio di una pagina web si intende un sistema che controlla,
tiene d'occhio, una pagina web nel corso del tempo e ne registra o ne
notifica all'utente eventuali cambiamenti. Può essere utile quando si
attende la pubblicazione di un contenuto web importante, che ci interessa,
permettendoci di non rimanere davanti allo schermo del PC.
Grazie agli strumenti messi a disposizione da ogni distribuzione Linux,
possiamo realizzare uno script bash che fa al caso nostro.
I tools di cui abbiamo bisogno sono wget,
diff e grep.
È necessaria inoltre un po' di familiarità con il terminale.
Lo script sarà composto da 3 parti principali: la prima che scarica la
pagina o parte di essa, la seconda che verifica se il contenuto è
cambiato, infine l'ultima che avverte l'utente in caso di cambiamento.
In questo articolo saranno illustrati principalmente due metodi per il
monitoraggio: uno manuale ed uno pianificato.
Panoramica sui tools
Qui si descriveranno brevemente i tools impiegati nella realizzazione di questo script. Chi conosce già il loro funzionamento può saltare questa parte iniziale.wget
wget è un tool non interattivo per il
download di pagine web, su cui si basa il nostro script. La sua
sintassi base è la seguente:
wget "www.glgprograms.it"
wget si collega al server www.glgprograms.it,
riceve in risposta una pagina html (nel caso specifico la
home page di questo sito) e la salva in un file nella cartella
di lavoro corrente col nome index.html.Si può modificare il nome del file di destinazione con l'opzione
-O (maiuscola!):
wget "www.glgprograms.it" -O "pagina.html"Un'altra opzione che risulterà utile più avanti è
-nc, che evita di sovrascrivere un file già
esistente quando si tenta di scaricarlo di nuovo.Nota: si consiglia di scrivere URL e percorsi sempre tra virgolette.
Per ulteriori opzioni e approfondimenti si rimanda alla documentazione ufficiale.
diff
diff è un altro tool incluso nei pacchetti
base di ogni distribuzione Linux. La sua funzione è quella di leggere in
input due file di testo, confrontarli e scrivere in output quelle parti
che differiscono. Di default l'output è sullo schermo, ma possiamo
redirezionarlo, ovvero deviarlo, tramite l'operatore
> su un file a nostra scelta, ed è
così che il nostro script farà.
Esempio:
diff file-1.txt file-2.txt > differenza.txt
| file-1.txt | file-2.txt | differenza.txt |
|---|---|---|
|
Oggi il cielo è sereno |
Oggi il cielo è nuvoloso |
2c2 < è sereno --- > è nuvoloso |
grep
Il terzo tool che utilizzeremo è grep.
grep analizza un file (di testo) e cerca
all'interno di esso una stringa generica. Questo strumento ci servirà
per estrarre alcune parti da un'intera pagina web. La sintassi base è:
grep "parola" "pagina.html"L'output, che per default è a video, conterrà tutte le righe del file che contengono quella parola. Nel nostro caso vorremo invece redirigere l'output su un file (che poi confronteremo con
diff, l'operatore è
>:
grep "stringa" pagina.html > file1.htmlCome solito, per ulteriori opzioni o approfondimenti si rimanda alla documentazione.
L'ultima nozione richiesta è quella di permessi di esecuzione. Per poter essere eseguito come programma lo script necessita infatti del flag x, che si abilita così:
chmod +x "script.sh"
Monitoraggio
A seconda delle necessità, si può optare per un monitoraggio manuale oppure
per uno pianificato.
Il primo è più semplice, ma adatto al controllo di
una pagina che sarà modificata entro alcune ore e della quale ci interessa
solamente una modifica. Esempio pratico: sapete che in giornata il sito X
metterà in vendita i biglietti per un certo evento, ma non volete rimanere
incollati al PC premendo compulsivamente F5 per aggiornare la pagina. Il
monitoraggio manuale calza a pennello!
Il secondo consente invece un monitoraggio pianificato, ideale per tenere
d'occhio un sito abitualmente. Esempio: il vostro blog o sito web preferito
è sprovvisto di una mailing list o di Feed RSS che vi avvertono quando un
nuovo articolo è pubblicato. Potete quindi pianificare il controllo ogni
giorno ad un'ora prefissata per non perdervi mai un aggiornamento!
Manuale
La versione manuale dello script deve essere eseguita, ovviamente,
manualmente dall'utente nel terminale. Il nucleo del codice
sotto riportato è il costrutto while, che
viene iterato ogni 60 secondi e controlla eventuali cambiamenti.
Le linee in rosso precedute da # sono commenti che, come in ogni
linguaggio, aiutano nella lettura del codice e sono ignorate durante
l'esecuzione dello stesso.
# Inserire tra virgolette l'URL del sito web da controllare URL="www.glgprograms.it" # Salva la pagina la prima volta wget -O "old.html" $URL # Ciclo while [ "$DIFF" == "" ] do # Attendi 60 secondi prima di proseguire sleep 60 # Scarica nuovamente la pagina wget -O "new.html" $URL # Confronta le due pagine e salva le differenze nella variabile DIFF DIFF=$(diff "old.html" "new.html") done # Notificare qui
Pianificato
Cron
Per pianificare l'avvio dello script e quindi il controllo di una pagina web, si ricorre all'utility di scheduling (pianificazione) che i sistemi UNIX-Like usano: cron. Supponiamo che lo script si trovi in questo percorso
/home/luca/monitor-website.she che io voglia eseguirlo tutti i giorni alle 21:00. Devo quindi modificare il file di configurazione di
cron:
crontab -ee aggiungere in fondo la seguente riga
00 21 * * * /home/luca/monitor-website.sh
 Sintassi base crontab
Sintassi base crontab
Consiglio: il comando crontab utilizza l'editor di testo
vi, che è molto ostico. (Link ad una
guida rapida
per chi dovesse rimanervi intrappolato ;) )Per modificare crontab con un editor più umano come
nano,
lanciare per prima cosa il seguente comando e poi editare crontab.
export EDITOR=nanoSe alla pianificazione e quindi alla reiterazione pensa
cron, lo script si semplifica:
# Inserire tra virgolette l'URL del sito web da controllare URL="www.glgprograms.it" # Salva la pagina la prima volta wget -nc -O "old.html" $URL # Scarica nuovamente la pagina wget -O "new.html" $URL # Confronta le due pagine e salva le differenze nella variabile DIFF DIFF=$(diff "old.html" "new.html") # Se la variabile DIFF non è vuota, c'è stato un cambiamento if [ "$DIFF" != "" ] then # Cancello la pagina vecchia e la sostituisco con la nuova rm old.html mv new.html old.html # Notificare qui fiNota: nel primo
wget si usa
l'opzione -nc, così che il file
old.html venga scaricato solo durante il
primo avvio dello script.
Anacron
Il metodo appena visto funziona ovviamente se il PC è acceso e pronto ad
eseguire lo script nell'ora specificata nella crontab.
Se non siamo sicuri che questo possa avvenire, si può ricorrere ad
anacron. A differenza di
cron permette infatti di eseguire lo script
giornalmente, in qualsiasi momento si accenda il PC. La configurazione
consiste semplicemente nello spostare il file eseguibile nella cartella
/etc/cron.daily. Una volta scritto e reso
eseguibile, lo spostamento deve essere fatto da utente root:
mv script.sh "/etc/cron.daily"
Notifica
A questo punto si deve scegliere un metodo per notificare l'utente adatto
al tipo di monitoraggio scelto. Il codice per la notifica va inserito
dove compare il commento Notificare qui nei
due esempi precedenti.
Notifica testuale
Questa modalità è applicabile solo quando si lancia manualmente lo script dal terminale, in quanto la notifica di avvenuto cambiamento è semplicemente scritta su schermo. La finestra dovrà quindi essere lasciata aperta finché lo script non termina (ovvero la pagina cambia), oppure finchè l'utente non decide di interrompere il controllo (premento Ctrl+C). L'unica linea da aggiungere sarà quindi:
echo "La pagina" $URL "è cambiata!"
Notifica grafica
Questa modalità è applicabile sia col monitoraggio manuale sia con quello pianificato. Quando avviene un cambiamento nella pagina, verrà visualizzata una piccola finestra di dialogo. Il comando da utilizzare cambia a seconda del Desktop Environment che si utilizza.
Gnome
Per coloro che utilizzano Gnome3, il Desktop Environment di Ubuntu, c'è
il tool zenity. La linea da aggiungere è:
zenity --info --title="Aggiornamento" --text="Il sito web sotto controllo è stato aggiornato!"
KDE
Per coloro che invece utilizzano KDE, il Desktop Environment di KUbuntu, c'è
il tool kdialog. Aggiungere quindi:
kdialog --title "Aggiornamento" --msgbox "Il sito web è stato modificato!"
Altri
Per Desktop Environment quali XFCE o LXDE, che non hanno un tool analogo
"out of the box", si consiglia di installare zenity.
Vedere quindi il paragrafo Gnome.
Casi disperati
Se avete installato un DE alternativo, molto leggero, potete
ricorrere al tool messo a disposizione direttamente dal server grafico
Xorg: xmessage.
xmessage "Il sito web e' stato modificato\!"Importante: se si pianifica l'avvio dello script con cron e si sceglie la notifica grafica è necessario, per ragioni che tralasciamo, aggiungere nello script all'inizio del codice la seguente linea:
export DISPLAY=:0
Notifica sonora
Un modo carino per notificare, ancora valido per entrambi i tipi di
monitoraggio, può essere la riproduzione di un file audio, un po' come
una sveglia. In questo esempio si usa vlc:
vlc /percorso/alla/canzone.mp3
Notifica tramite E-Mail
Se si possiede un server personale dotato di servizio mail (link ad un nostro articolo su come installare un mailserver), è possibile lanciare lo script su tale server e inviare un'email al proprio indirizzo quando lo script ha successo.
echo "Il sito web" $URL "è stato modificato." | mail -s "Monitor Website" nome@mail.it
Notifica tramite Telegram
Per chi non lo conoscesse, Telegram è un servizio di messaggistica. Tra le sue potenzialità, vi è la possibilità di creare un Bot, ovvero un utente virtuale programmabile, che può nel nostro caso essere lanciato dallo script di monitoraggio e inviare un vero e proprio messaggio di chat al vostro account. Per i dettagli su come configurare un Bot rimandiamo a questa guida. Arrivando direttamente alla conclusione, la riga da aggiungere allo script sarà:
wget "https://api.telegram.com/botTOKEN/sendMessage?chat_id=ID&text=Il sito web $URL è stato modificato!" -O /dev/nullDove TOKEN è il codice segreto del vostro Bot e ID è l'ID del vostro utente Telegram.
Opzioni avanzate
Trattiamo adesso due funzionalità utili che possono essere aggiunte al nostro script di monitoraggio. Queste richiedono alcune conoscenze di HTML e sono rivolte in generale ad un utente più esperto, ma cercherò di descriverle nel modo più chiaro possibile così da permettere a chiunque di integrarle nel proprio programma.
Monitorare parte di una pagina
In certi casi c'è la necessità (o addirittura l'obbligo) di monitorare
non un'intera pagina web, ma soltanto una parte di essa. Vediamo perchè.
Supponiamo di voler monitorare la home page di questo
sito in modo pianificato, così da ricevere una notifica ogni volta che
viene pubblicato un nuovo articolo. Lo script verrà quindi lanciato da
cron con una cadenza regolare, ma il codice HTML
della pagina sarà diverso ogni volta, anche se non ci sono nuovi articoli.
Come mai? Perchè nella nostra home page, a destra, c'è una slideshow di foto
automatica che rende il codice HTML diverso (in quanto contiene un'immagine
diversa). Questo vale per ogni sito web che contenga dei contenuti dinamici
come pubblicità, gallerie fotografiche, contatori di visite e così via.
Per ovviare al problema e concentrarci sul contenuto che ci interessa
eliminando ogni contenuto variabile non voluto sfruttiamo il tool
grep. Come prima cosa dobbiamo aprire la
pagina web che ci interessa, fare click destro sul contenuto specifico e
scegliere Ispeziona (se usate Chrome/Chromium) o
Analizza elemento (se usate Firefox).
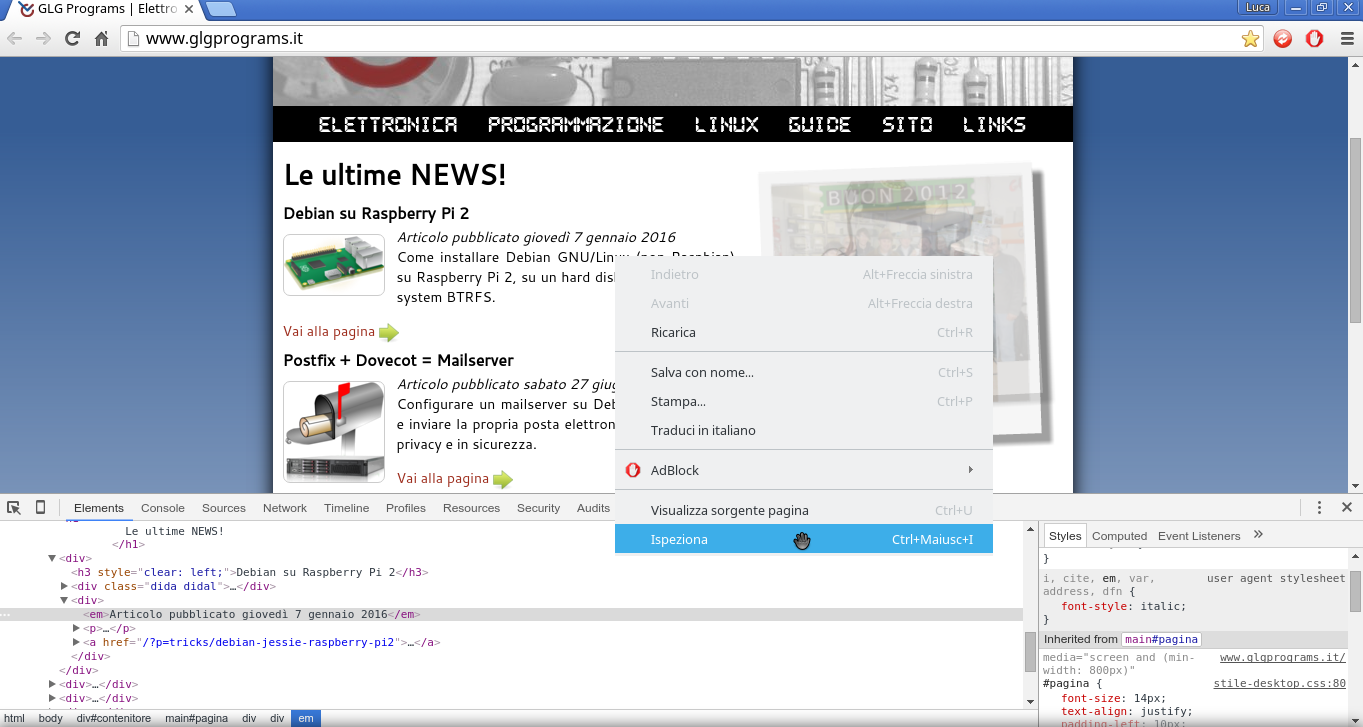
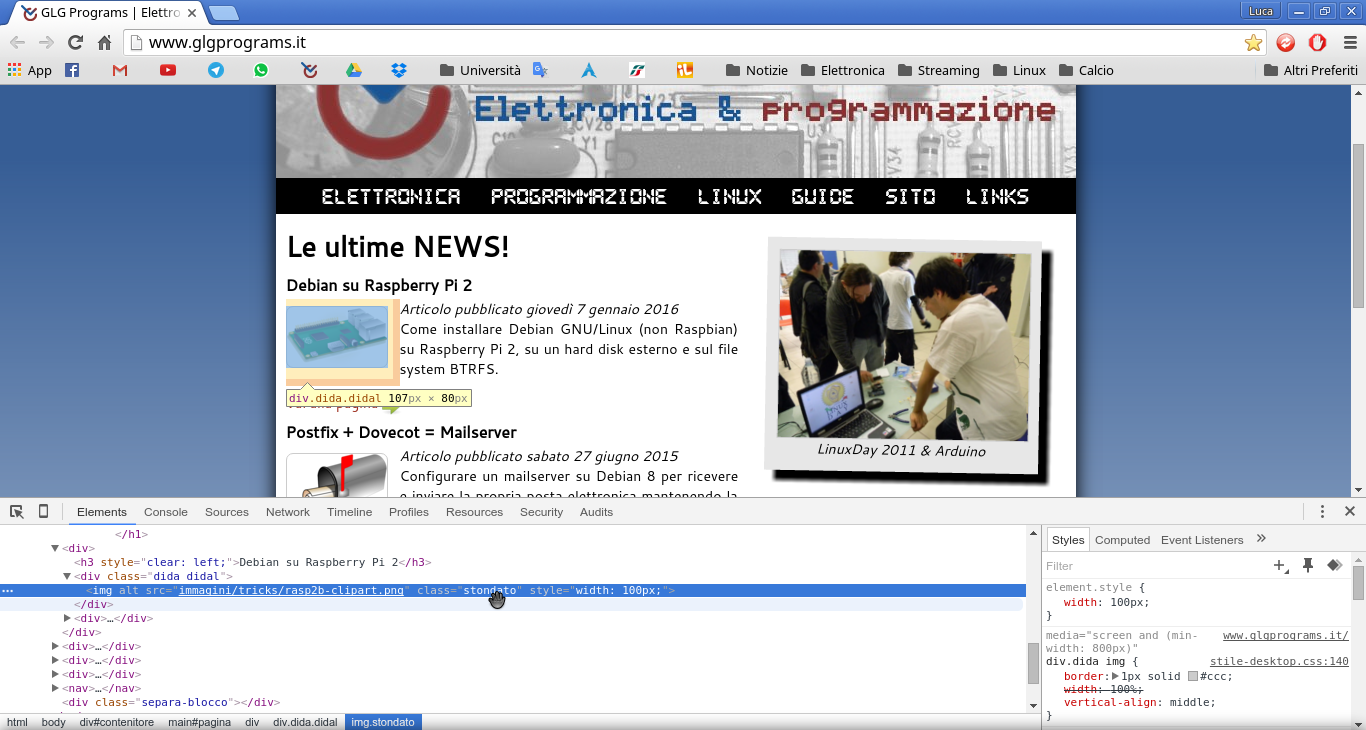
class="stondato"Possiamo quindi sfruttare
grep e
restringere il monitoraggio selezionando solo quelle parti che contengono
la classe "stondato", ovvero solo gli articoli. Mostriamo l'utilizzo di
grep direttamente nello script:
# Inserire tra virgolette l'URL del sito web da controllare URL="www.glgprograms.it" # Salva la pagina la prima volta wget -nc -O "old.html" $URL # Attendi 60 secondi prima di proseguire sleep 60 # Scarica nuovamente la pagina wget -O "pagina.html" $URL # Estraggo solo gli articoli grep 'class="stondato"' pagina.html > new.html # Confronta le due pagine e salva le differenze nella variabile DIFF DIFF=$(diff "old.html" "new.html") # Se la variabile DIFF non è vuota, c'è stato un cambiamento if [ "$DIFF" != "" ] then # Cancello la pagina vecchia e la sostituisco con la nuova rm old.html mv new.html old.html # Notificare qui fi
Monitorare una pagina che richiede login
L'ultimo caso particolare che descriviamo è quello in cui la pagina
interessata sia visibile solamente dopo aver effettuato un login con
username e password. Le potenzialità di wget
permettono di assolvere anche questo compito. Il monitoraggio si divide
in due fasi:
- Eseguire il login e salvare il cookie
- Accedere alla pagina interessata tramite il cookie salvato
Attenzione_1! Il vostro username e password saranno presenti, leggibili, nello script oppure nella history del terminale (se avete lanciato il comando manualmente). Se dovete ricorrere al monitoraggio con login, assicuratevi che questi file non siano accessibili da altre persone. Si sconsiglia inoltre di utilizzare il login su pagine con dati sensibili come conti bancari, etc.
Attenzione_2!
wget
supporta il protocollo HTTPS, quindi la comunicazione dei dati di accesso
avverrà in modo cifrato sui siti web che utilizzano tale protocollo.
Effettuate invece il login tramite HTTP semplice a vostro rischio e pericolo.
Login
Per prima cosa dobbiamo accedere alla pagina di login e analizzare, con il procedimento illustrato sopra, le caselle di immissione. La situazione che si presenta somiglierà a questa: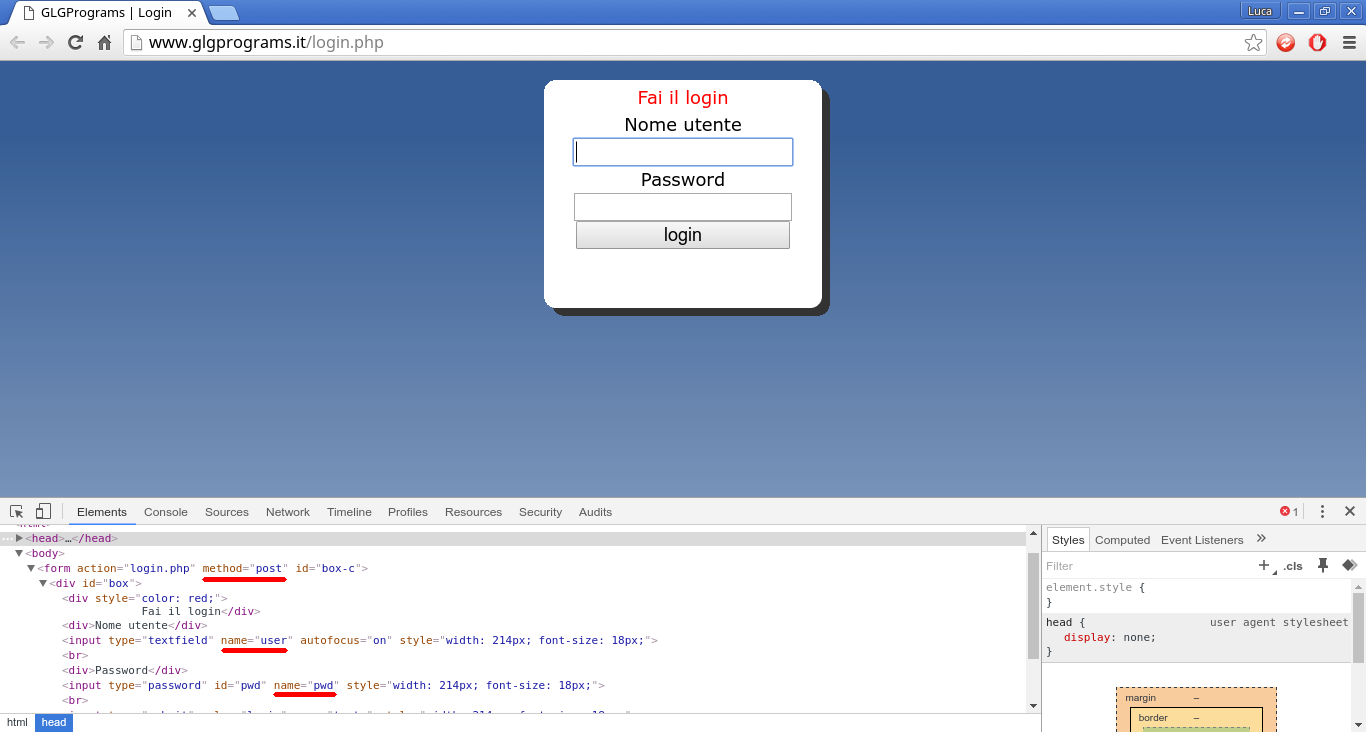
- Il metodo di trasmissione del form: GET o POST, anche se tutti i form che si trovano, a meno di casi eccezionali, sono di tipo POST in quanto più sicuri. Il tipo GET infatti comunica username e password direttamente nella barra dell'indirizzo.
- Il name della casella dell'username.
- Il name della casella della password.
wget i seguenti
parametri:
wget --save-cookies=cookie.txt --keep-session-cookies --post-data="user=il_tuo_username&pwd=la_tua_password" "www.sito.it/login.php"dove
user e pwd
sono i due campi name presi dall'immagine
sopra. Il cookie verrà salvato nel file cookie.txt
nella cartella corrente. Il nome cookie.txt
ovviamente non è obbligatorio, ma è solo un promemoria per il suo scopo.
Se si desidera salvarlo in una cartella diversa, aggiungere il percorso:
--save-cookies="/percorso/alla/cartella/cookie.txt"Questo comando avrà anche l'effetto di salvare la pagina di login vera e propria. Se si vuole eseguire più volte questo comando (pianificandolo) si consiglia di aggiungere
-O /dev/nullche salverà la pagina nel device speciale null, ovvero da nessuna parte.
A questo punto siamo pronti per il download della pagina.
Accesso
Il comandowget eseguirà quindi l'accesso
servendosi del cookie salvato in precedenza, che viene caricato così:
wget --load-cookies="cookies.txt" "www.sito.it/pagina_interessata.html" -O pagina.html
Download
Per concludere, riportiamo 3 diversi script completi e funzionanti, con la relativa configurazione dicrontab dove
necessario.Nota: adattare i percorsi delle cartelle per il proprio utente e impostare i permessi di esecuzione per gli script.
Script 1: monitoraggio manuale di parte di una pagina e notifica sonora.
Script 2: monitoraggio pianificato ogni giorno alle 21:00 di una pagina e notifica grafica in ambiente KDE.
Script 3: monitoraggio pianificato ogni domenica alle 18:00, pagina con login e notifica email. Ricordarsi di effettuare prima il login salvando il cookie nel file
cookies.txt.
